
Technology
Industry
Cohere outperforms competitors in agentic enterprise tasks with Apollo evaluations
Featuring Wojciech Galuba, Director of Data & Evaluations at Cohere
Overview
Cohere matches or outperforms its competitors across agentic enterprise tasks via Apollo evaluations.

The results


“We appreciated Apollo’s ability to stand up a project quickly, pivot when needed, and deliver high-quality data that consistently improved model performance.”
Client Profile
Cohere is a leading security-first enterprise AI company. It builds cutting-edge foundation models and end-to-end solutions tailored for enterprise-scale applications. Its latest model, Command A, is a state-of-the-art, and highly efficient, generative model for enterprises in regulated industries.
Key Solution
Apollo Embedded Training & System Evaluations
The Challange
We needed to evaluate Command A to see if it delivers the right outcomes in specialized, real-world scenarios. Off-the-shelf benchmarks can signal that general model performance is good, while in reality it fails with niche use cases. We needed PhD level experts across a range of specialisms, including STEM, Math, SQL, and subject matter experts in HR, retail and aviation, for blind annotation.
The Outcome
Cohere expanded into 10 languages with our expert annotators, with fine-tuning in rare programming languages to tackle specialized use cases, for transformative improvements in model performance.
Client Interview
Q: Wojciech, tell us more about the specific problem you faced?
To optimize Command A, we needed to understand how well it performed in enterprise scenarios, such as customer service or HR queries. We weren’t just looking for accuracy in responses, but nuance — did the model understand tone, context, ambiguity? We needed smart, consistent, scalable human evaluations to tell us that.

“Apollo has been a trusted partner and their dedication to quality and results have been key to our success.”
Q: What made you think Apollo could make a difference?
We had partnered with Apollo previously, to train our Command R model for hallucination reduction, and consider them a valued partner that helps us win in the marketplace. The Apollo team is passionate when it comes to improving our models. We’ve trusted them with critical challenges, and their commitment to quality ensures we can develop a best-in-class model.
Q: How did quality improve with Apollo?
They maintain a really high bar for talent, with continuous observability that ensures we can trust the data. And they’re not afraid to challenge us, posing really complex questions that push us to create better data.
The result was that Command A is as good as, and in some cases much better than, its competitors at consistently answering in the requested language. For example, take Arabic dialects–its ADI2 score (a human evaluation metric) achieved a 9-point lead over GPT-4o and DeepSeek-V3.
Q: What was the commercial impact?
In head-to-head human evaluation across business, STEM, and coding tasks, Command A matches or outperforms its larger competitors, while offering superior throughput and increased efficiency. Command A excels on business-critical agentic and multilingual tasks, while being deployable on just two GPUs, compared to other models that typically require as many as 32. Human evaluations drove this success because they test on real-world enterprise data and situations.
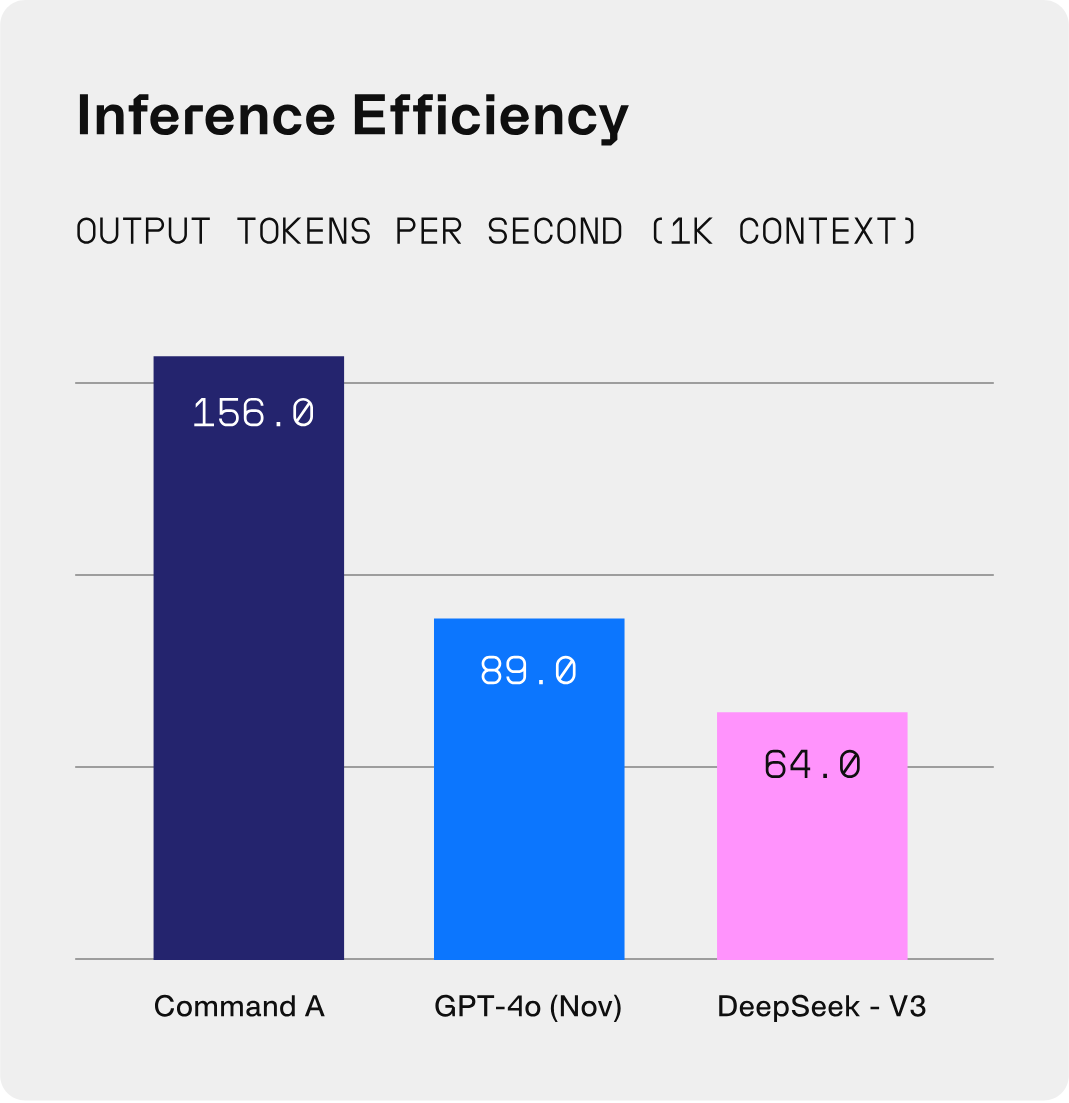
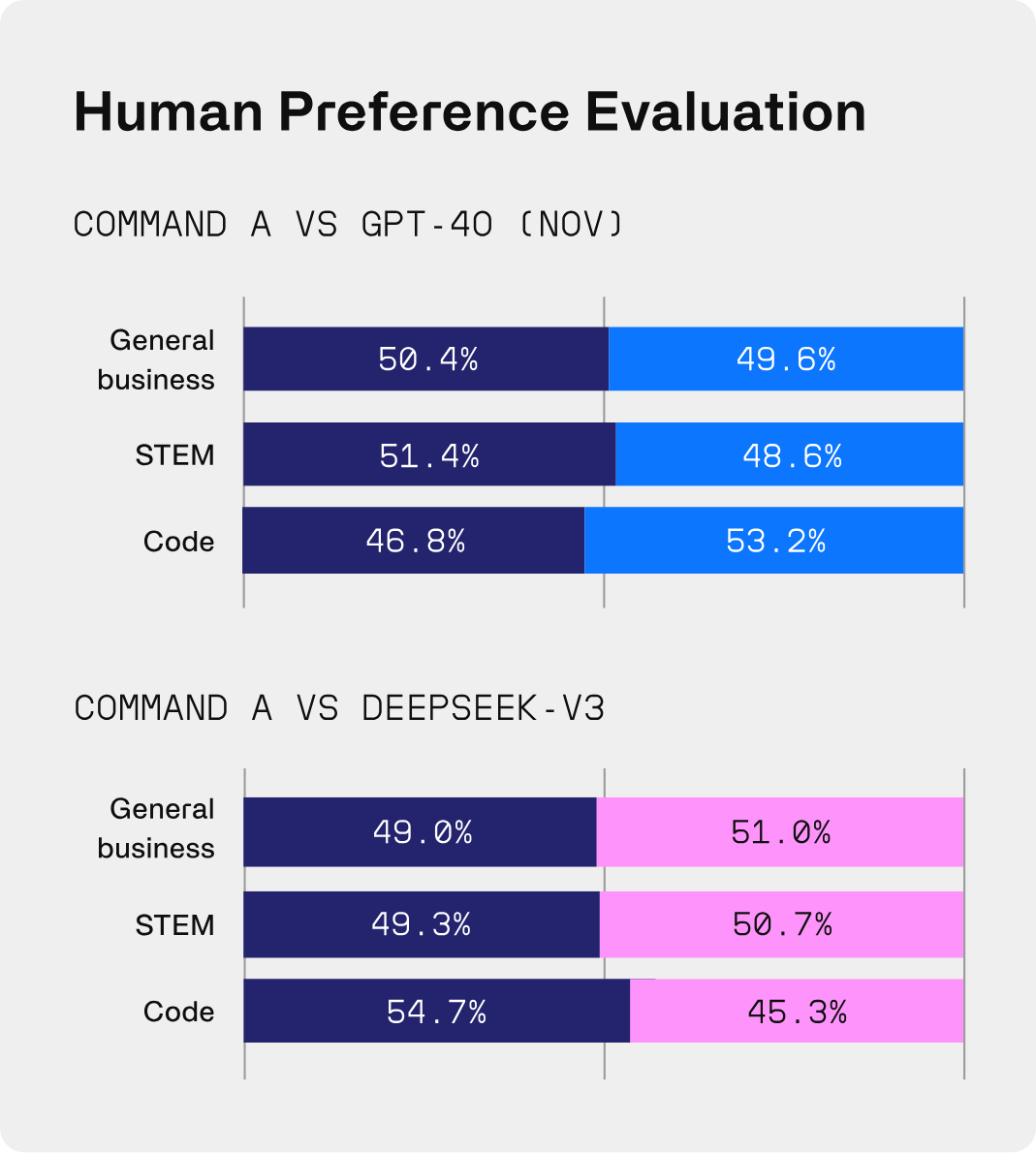
Head-to-head human evaluation win-rates on enterprise tasks. All examples are blind-annotated by Apollo human annotators, assessing enterprise-focused accuracy, instruction following, and style. Throughput comparisons are between Command A on the Cohere platform, GPT-4o and Deepseek-V3 (TogetherAI) as reported by Artificial Analysis.
